Tools for Thought
Eine neue Software-Generation für das persönliche Wissensmanagement
4 Digitale Werkzeuge für das persönliche Wissensmanagement
Es gibt unzählige Apps, die das persönliche Wissensmanagement im Sinne des 4C-Modells unterstützen. Sie ermöglichen es, gemäss der Zettelkasten-Methode zu arbeiten, ohne sich mit einem physischen Zettelkasten herumschlagen zu müssen. Sie gestalten das Erstellen und Wiederfinden von Notizen sehr viel effizienter, und sie bieten über die Volltextsuche eine weitere Zugriffsmöglichkeit auf die Wissensbasis, von der Luhmann nur träumen konnte.
Allerdings gibt es sehr unterschiedliche Ansätze, und nicht alle eignen sich gleich gut, wenn man sein persönliches Wissen konsequent und langfristig managen möchte. Populäre Apps wie Evernote oder OneNote erfüllen zwar viele Anforderungen, haben aber auch einige prinzipielle Limitierungen. Dies erklärt, warum in den letzten Jahren Apps wie Roam Research, Logseq oder Obsidian entstanden und in kürzester Zeit populär geworden sind.
In diesem Kapitel werden die Konzepte, Möglichkeiten und Vorteile dieser Tools for Thought erläutert.
4.1 Vorläufer: Outliner und Wikis
Wollte man das Konzept der Tools for Thought in einem einzigen Satz erklären, könnte man sagen: Es handelt sich um eine Kombination aus Outliner und Wiki. Es ist deshalb hilfreich, sich vor Augen zu führen, was die Besonderheiten dieser beiden Software-Gattungen ausmachen.
4.1.1 Outliner
Ein Outliner organisiert Information in hierarchischen Aufzählungen. Er eignet sich insbesondere dafür, eine grössere Menge von Informationen effizient zu strukturieren. So kann man die Reihenfolge der Aufzählungspunkte sehr einfach anpassen und durch Einrückungen Unterthemen bilden.
Zwar lassen sich mit fast jeder Software in irgendeiner Form Aufzählungen erstellen – beispielsweise mit Word oder PowerPoint. Ein Outliner zeichnet sich jedoch dadurch aus, dass sämtliche Inhalte in Aufzählungen organisiert sind. Beispiele für solche Outliner sind Workflowy, CheckVist oder Dynalist.
4.1.2 Wikis
Ein Wiki ist eine Sammlung von einzelnen Seiten, die einander gleichgestellt sind und keine bestimmte Reihenfolge haben. Inhaltliche Bezüge werden ausschliesslich über Links auf andere Seiten hergestellt. Ein Wiki ist insofern das pure Gegenteil eines Outliners, als es Information nicht in einer Hierarchie, sondern in einem Netzwerk organisiert.
Wikis sind Hypertext-Systeme, und als solche lösen sie ein grundlegendes Problem von hierarchischen Informationsstrukturen: Eine bestimmte Information muss nicht einem einzigen Thema zu- bzw. untergeordnet werden, sondern man kann es mit beliebig vielen anderen Themen in Beziehung setzen. Auch der spätere Zugang zu dieser Information ist nicht nur über einzigen Pfad entlang der Themenhierarchie möglich, sondern jeder Link ist eine Möglichkeit, die Information wiederzufinden.
Auch hier kann man argumentieren, dass Links in vielen Apps existieren. Kennzeichnend für Wikis ist, dass diese Links das einzige Organisationsprinzip darstellen. Zudem können Links besonders einfach erstellt werden: Indem man einen Begriff in eine Doppelklammer setzt, wird er bereits zu einem Link auf die Seite mit dem entsprechenden Titel. Und sollte die betreffende Seite noch nicht existieren, wird sie automatisch angelegt. Nicht von ungefähr geht die Bezeichnung «Wiki» auf das hawaiianische Wort für «schnell» zurück.
Ähnlich wie bei den Outlinern geht es also auch bei den Wikis darum, Information möglichst effizient zu organisieren – nur dass das Ordnungsprinzip ein anderes ist. Beispiele für Wikis sind MediaWiki (auf dem die Wikipedia basiert), Confluence, DokuWiki oder TiddlyWiki.
4.2 Tools for Thought: Allgemeines
4.2.1 Terminologie
Wie bereits in der Einleitung erwähnt, hat sich für die Software-Kategorie, um die es hier geht, noch kein allgemein akzeptierter Begriff herausgebildet – schon gar nicht im deutschen Sprachraum. Im Englischen wird oft von Note-Taking App, Personal Knowledge Management App oder Zettelkasten App gesprochen. Diese Bezeichnungen scheinen mir jedoch nicht spezifisch genug.
Timon Burckhardt schlägt den Begriff Referenzeditor vor. [29] Das ist insofern ein interessanter Ansatz, als er die Bedeutung der Vernetzung der einzelnen Informationseinheiten betont («Referenz» ist hier im Sinne von «Verweis» bzw. «Link» zu verstehen). Noch einen Schritt weiter geht Ramses Oudt, der von Networked Thinking Tools spricht. [30] Diese Bezeichnung macht deutlich, dass die Möglichkeiten zur Vernetzung das kreative Denken unterstützen. Einer ähnlichen Logik folgt der Begriff Tools for Thought; da dieser vergleichsweise populär ist, habe ich ihn für diese Arbeit übernommen – im Bewusstsein, dass auch er nicht ganz trennscharf ist.
4.2.2 Definition
Die Apps, die ich als Tools for Thought bezeichne, besitzen folgende Eigenschaften und Funktionen:
- Sie speichern Informationen nicht in einzelnen Dokumenten, sondern in einer Datenbank.
- Sie bieten die Funktionen eines Outliners, indem man Informationen in einer hierarchischen Struktur gliedern kann.
- Sie bieten die Funktionen eines Wikis, indem man über Links sehr einfach auf andere Informationen verweisen kann.
- Sie bieten bidirektionale Links, d.h. auf jeder Seite werden alle anderen Seiten aufgelistet, die auf aktuelle Seite verlinken.
- Sie erlauben es, einzelne Informationseinheiten (Absätze, Blöcke) an beliebiger Stelle wiederzuverwenden (sog. Transklusionen).
Ferner besitzen Tools for Thought typischerweise die folgenden Funktionen, die ich allerdings nicht als zwingend erachte:
- Sie bieten eine visuelle Darstellung der Verlinkungen.
- Sie erlauben es, Informationen nicht nur über eine Volltextsuche, sondern auch über sogenannte Queries zu finden.
- Sie bieten ein Journal.
4.2.3 Produkte
Es kann hier nicht darum gehen, eine Marktübersicht der Tools for Thought zu bieten. Vielmehr möchte ich zwei Apps kurz vorstellen, die ich selbst ausführlich getestet habe und somit vertieft kenne. Weitere Tools for Thought sind im Software-Verzeichnis im Anhang zu finden.
Roam Research (meist nur Roam genannt) ist mutmasslich der populärste Vertreter der Tools for Thought. Die App wurde erstmals im Oktober 2019 als Public Beta einer grösseren Benutzerschaft zugänglich gemacht und steht heute als kostenpflichtige Web App oder Mobile App zur Verfügung. Sie speichert ihre Daten wahlweise in der Cloud oder lokal auf dem Rechner des Benutzers. Die treibende Kraft hinter Roam Research, Inc. ist der Gründer und CEO Conor White-Sullivan, der allerdings seit einiger Zeit wegen seiner Kommunikations- und Produktpolitik in der Kritik steht. Finanziell dürfte das Unternehmen gut aufgestellt sein – einerseits dank der frühen Monetarisierung seiner App, andererseits dank einer ersten Finanzierungsrunde über 9 Mio. US-Dollar im September 2020 (zu einer Bewertung von 200 Mio. US-Dollar).
Logseq ist von der Benutzeroberfläche und vom Funktionsumfang her mit Roam vergleichbar. Allerdings haben die Entwickler um Tienson Qin in einigen entscheidenden Punkten einen grundlegend anderen Ansatz gewählt. So ist Logseq Open Source Software und kostenlos nutzbar. Zudem werden die Daten ausschliesslich lokal im gängigen Markdown-Format gespeichert, was Vorteile hinsichtlich des Datenschutzes und der Migrationsfähigkeit mit sich bringt. Allerdings ist ein kostenpflichtiger Synchronisierungsdienst in der Cloud in Vorbereitung, der die parallele Nutzung auf mehreren Geräten vereinfachen soll. Logseq, Inc. konnte im Mai 2022 ebenfalls eine erste Finanzierungsrunde über 4.1 Mio. US-Dollar abschliessen und dafür einige bekannte Persönlichkeiten aus dem Silicon Valley als Investoren gewinnen.
4.3 Tools for Thought: Konzepte und Funktionen
In diesem Kapitel soll beschrieben werden, wie die in Kap. 4.2.2 Definition genannten Konzepte und Funktionen konkret aussehen und welchen Nutzen sie für das persönliche Wissensmanagement bringen. Diese Beschreibungen erfolgen teilweise textuell, teilweise über die referenzierten Videos; Text und Video ergänzen sich also und sind inhaltlich nicht deckungsgleich.
4.3.1 Eine einzige Datenbank
Sowohl Roam als auch Logseq speichern Informationen in einer Graph-Datenbank. Sie folgen also dem bereits beschriebenen Prinzip, sämtliche Notizen in einer einzigen Wissensbasis und nicht in einzelnen Dateien zu verwalten. [31]
Zwar ist es technisch möglich, mehrere separate Graphen zu nutzen. Allerdings ist das nur dann sinnvoll, wenn man voneinander völlig unabhängige Wissensbereiche bearbeiten oder private und geschäftliche Daten strikt trennen möchte. Beide Apps können immer nur einen einzigen Graphen geöffnet halten, und es sind auch keine Links auf Seiten eines anderen Graphen möglich.
Auch aus Gründen der Performance ist es nicht erforderlich, mehrere Graphen zu nutzen: Selbst bei grossen Informationsmengen, vielen Seiten und intensiver Verlinkung ist die Arbeit mit Roam und Logseq ausgesprochen flüssig. Dies hat unter anderem mit den Besonderheiten einer Graph-Datenbank zu tun: Sie handhabt Verbindungen zwischen Datenobjekten wesentlich effizienter als eine relationale Datenbank.
4.3.2 Outliner-Funktionen
Auf den ersten Blick unterscheiden sich Roam und Logseq nicht von einem Outliner wie z.B. Workflowy. Jeder Absatz bildet einen Aufzählungspunkt – nur dass man in diesem Fall von einem Block spricht. Blocks können über Tastaturbefehle oder mit der Maus nach oben bzw. unten verschoben und auf gleiche Weise ein- bzw. ausgerückt werden.
Dank den Outliner-Funktionen können beispielsweise Informationen zu den verschiedenen Varianten einer politischen Initiative folgendermassen strukturiert werden:

Wer möchte, kann zudem einzelne Blöcke als Zwischentitel (H1 bis H6) formatieren, um eine Seite noch besser zu strukturieren. Zwischentitel werden optisch anders dargestellt, funktionieren aber ansonsten wie normale Blöcke.
Um sich auf einer umfangreichen Seite einen besseren Überblick zu verschaffen, kann man untergeordnete Blöcke per Mausklick aus- oder einblenden. Dies funktioniert nicht nur mit einzelnen Blöcken, sondern auch mit ganzen Teilbäumen.
Möchte man sich hingegen auf einen einzelnen Block oder Teilbaum fokussieren, kann man ebenfalls per Mausklick nur diesen anzeigen lassen. In welchen Kontext der Block gehört, lässt sich dabei an einer Art Breadcrumb-Navigation ablesen, über die man wieder zum übergeordneten Block zurückkehren kann.
Das folgende Video demonstriert diese grundlegenden Outliner-Funktionen:
4.3.3 Wiki-Funktionen
Interne Links (also Links auf andere Seiten innerhalb eines Graphen) funktionieren in den Tools for Thought genau gleich wie in einem Wiki: Man setzt doppelte eckige Klammern um ein Wort oder eine Wortfolge und verlinkt dadurch auf die Seite mit dem entsprechenden Titel. Sollte es noch keine Seite mit diesem Titel geben, wird sie automatisch erstellt.
Damit das funktioniert, müssen Seitentitel eindeutig sein, d.h. es kann nicht zwei Seiten mit demselben Titel geben. Man könnte das als Einschränkung sehen, aber eigentlich ist es ein Vorteil: Es verhindert Redundanz, weil man nicht versehentlich mehrere Seiten zum gleichen Stichwort anlegen kann.
Selbstverständlich ist es trotzdem möglich, mehrere Seiten zum gleichen Thema, aber mit unterschiedlichen Seitentiteln anzulegen. Sollte dies nicht absichtlich, sondern versehentlich geschehen, kann man zwei Seiten ganz einfach zusammenführen, indem man sie nachträglich gleich benennt.
Falls man zwar weiss, dass bereits eine Seite zu einem Thema existiert, sich aber nicht mehr an den genauen Titel erinnert, kann man direkt beim Setzen eines neuen Links die existierenden Seitentitel durchsuchen: Dazu öffnet man eine Doppelklammer und befindet sich automatisch in einem Suchdialog.

Eine Besonderheit der Tools for Thought besteht darin, dass man interne Links nicht nur über Doppelklammern setzen kann. Auch das Rautezeichen (#) direkt vor einem Wort sowie ein doppelter Doppelpunkt (::) direkt nach einem Wort erzeugen einen Link. Während die Variante mit dem Rautezeichen so genutzt wird wie Hashtags in den Sozialen Medien, ist der doppelte Doppelpunkt für sogenannte Attributes (Roam) bzw. Properties (Logseq) gedacht. Diese dienen dazu, Eigenschaften zu erfassen – bei Büchern beispielsweise Untertitel, Autor, Erscheinungsjahr und ISBN.

Dies sorgt zunächst für eine Formatierung, welche die Attributes bzw. Properties als solche erkennbar macht. Zudem kann man sie für spezielle Suchabfragen nutzen – diese sind allerdings nicht in allen Tools for Thought gleich implementiert. So kann man in Roam über sogenannte Attribute Tables alle Seiten, die ein bestimmtes Attribut haben, tabellarisch darstellen. Durch den Code {{attr-table: ISBN}} wird beispielsweise eine Tabelle mit allen erfassten Büchern generiert (soweit ihre ISBN vermerkt wurde).

Solche Tabellen lassen sich auch in Logseq generieren, nur dass hier zusätzlich Eigenschaftswerte als Selektionskriterium genutzt werden können. So kann man sich beispielsweise nur die Veröffentlichungen eines bestimmten Autors auflisten lassen.

Das Konzept der Attributes bzw. Properties ist derzeit noch nicht ausgereift, weshalb ich es nicht weiter vertiefe. Der Ansatz scheint mir aber interessant, weil er es erlaubt, mit den Tools for Thought auch strukturierte Daten zu verwalten. Und dies wiederum ermöglicht es, Notizen nicht nur per Volltextsuche zu durchsuchen, sondern nach unterschiedlichen Kriterien zu filtern, zu gruppieren und zu sortieren.
Ebenfalls uneinheitlich gelöst ist die Verlinkung von Synonymen und anderen Begriffsvarianten. Wenn der verlinkte Text exakt dem Titel der verlinkten Seite entsprechen muss, dann ist dies in der Praxis sehr einschränkend. Denn oft existieren für dieselbe Sache mehrere gleichwertige Begriffe, vielleicht auch Fremdwörter oder Abkürzungen, die alle auf dieselbe Seite verlinken sollen. In den meisten Tools for Thought gibt es dafür das Konzept des Alias, das allerdings unterschiedlich (und unterschiedlich gut) implementiert ist. Auch diesen Punkt möchte ich an dieser Stelle nicht vertiefen und verweise stattdessen auf die Untersuchung von Alexander Rink. [32]
Das folgende Video zeigt den Umgang mit Links in Logseq:
4.3.4 Bidirektionale Links
Wenn man ein herausragendes Merkmal der Tools for Thought nennen müsste, dann wäre es sicher die bidirektionale Verlinkung.
Dieses Konzept ist schon viele Jahrzehnte alt. Bereits der Memex – eine Vision von Vannevar Bush in seinem Artikel «As We May Think» aus dem Jahr 1945 [33] – sah Verknüpfungen zwischen Dokumenten vor, die in beide Richtungen funktionieren. Bidirektionale Links wurden auch vom Hypertext-Pionier Ted Nelson propagiert, dessen Project Xanadu es allerdings nie bis zur Marktreife schaffte. [34] Auch sonst scheint es lange Zeit keine brauchbaren Implementierungen gegeben zu haben – erst in den letzten paar Jahren wurde das Konzept durch die Tools for Thought populär.
Bei der bidirektionalen Verlinkung sind Links nicht nur auf der verlinkenden, sondern auch auf der verlinkten Seite sichtbar. Im folgenden Beispiel enthält die Seite A Links auf die Seiten B und C, ferner verlinkt die Seite C auf die Seite B. Bei unidirektionalen Links, wie wir sie beispielsweise aus dem Word Wide Web kennen, ist auf der Seite B nicht erkennbar, dass zwei andere Seiten auf sie verlinken.

Bei bidirektionalen Links der Tools for Thought hingegen werden die beiden eingehenden Links unten auf der Seite B im Abschnitt Linked References aufgelistet und können entsprechend zurückverfolgt werden. Die Tools for Thought gehen allerdings noch einen entscheidenden Schritt weiter: Sie zeigen nicht einfach nur den Titel der verlinkenden Seite an, sondern auch den Kontext, in dem der Link steht. (Andy Matuschak nennt deshalb die Linked References auch Contextual Backlinks.) [35]
Ein Beispiel: Auf der Seite «Parlament» gibt es (etwa in der Mitte) einen Link auf die Seite «Kantonsparlament»:
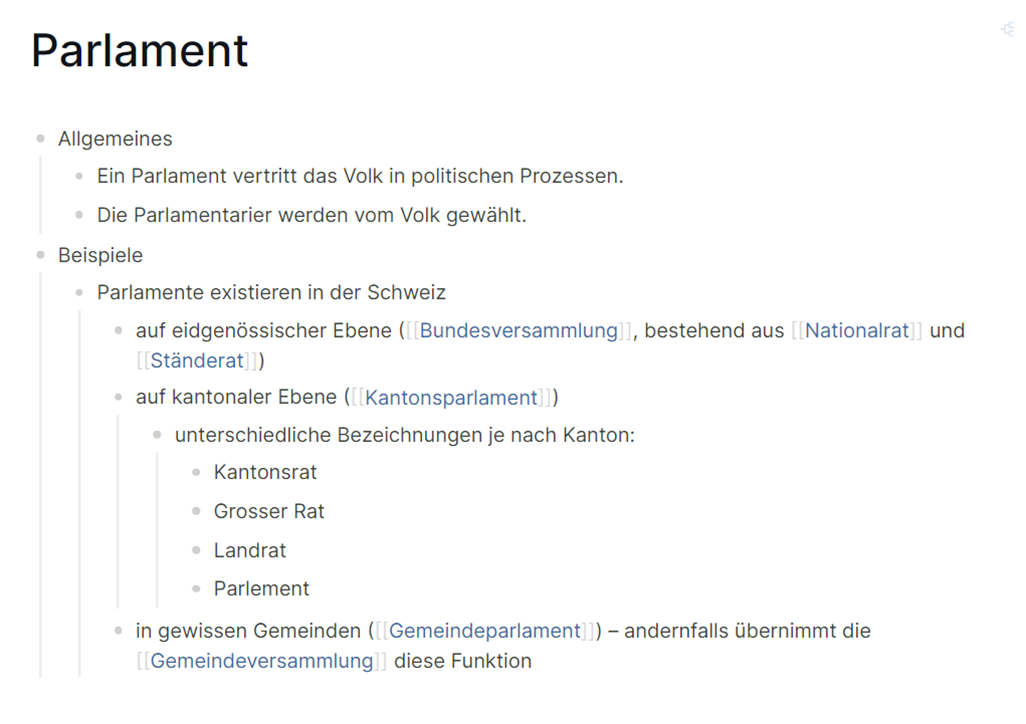
Auf der Seite «Kantonsparlament» wird dieser eingehende Link wie folgt dargestellt:

Diese Darstellung ist nach folgendem Prinzip aufgebaut:
- Im ersten Absatz steht der Titel der verlinkenden Seite («Parlament»). Durch einen Klick auf diesen Titel gelangt man bei Bedarf direkt zur entsprechenden Seite.
- Im zweiten Absatz folgen die direkt übergeordneten Blöcke in der Outliner-Hierarchie (unter Umständen gekürzt). Auch diese sind in der Regel klickbar und blenden dann die übrigen Blöcke gleicher Stufe ein.
- Im dritten Absatz wird der Block angezeigt, der den Link enthält.
- Ab dem vierten Absatz folgen allfällige untergeordnete Blöcke.
Eine weitere Besonderheit der Tools for Thought besteht darin, dass sie zwischen Linked References und Unlinked References unterscheiden. Die Linked References sind die eingehenden Links, wie wir sie gerade im obigen Beispiel gesehen haben. Unter den Unlinked References hingegen werden zusätzliche all jene Seiten bzw. Blöcke aufgeführt, die ebenfalls den entsprechenden Begriff enthalten, aber ohne einen Link. Auf diese Weise findet man weitere einschlägige Stellen, auch wenn diese nicht explizit verlinkt wurden.
Auf der Seite «Kantonsparlament» könnte dies beispielsweise folgendermassen aussehen:

Die Vorteile der bidirektionalen Links bzw. ihrer Anzeige in Form von Linked References sind vielfältig:
- Zunächst ersparen sie es einem, zusammenhängende Themen immer wechselseitig verlinken zu müssen – was man in der Praxis niemals konsequent schafft. Bei Systemen mit bidirektionalen Links genügt ein einzelner Link, um den Zusammenhang auf beiden Seiten erkennbar zu machen. Dadurch entsteht ein wesentlich dichteres Netz an Verweisen.
- Die Anzahl der Linked References ist ein guter Indikator für die Relevanz einer Seite – ähnlich wie beim PageRank der Google-Suche oder bei der Zitierhäufigkeit von wissenschaftlichen Publikationen.
- Weil Linked References nicht nur den reinen Link, sondern auch dessen Kontext darstellen, muss man weniger oft auf verlinkende Seiten wechseln, um die Zusammenhänge zu verstehen. Dadurch reduziert sich nach meiner eigenen Wahrnehmung auch das «Lost in Hyperspace»-Problem.
- Sowohl die Linked References als auch die Unlinked References machen viele Volltextsuchen überflüssig: Die Fundstellen zu einem Begriff werden automatisch präsentiert, und so erkennt man Bezüge, auf die man sonst vielleicht nie gekommen wäre. So gesehen fördern die References auch die Serendipität.
- Es ist letztlich nicht relevant, wo man eine Notiz ablegt: Solange man einen Link auf das zugehörige Thema setzt, wird die Notiz über die Linked References automatisch auf der entsprechenden Seite erscheinen. Das ist eine nicht zu unterschätzende Entlastung beim Erstellen von Notizen.
Das folgende Video zeigt, wie die bidirektionale Verlinkung in Logseq funktioniert:
4.3.5 Transklusionen
Eine zweite Besonderheit der Tools for Thought sind sogenannte Transklusionen. Dieses Konzept geht ebenfalls auf Ted Nelson zurück.
Als Transklusion bezeichnet man die Einbettung von Teilen eines elektronischen Dokuments in ein anderes elektronisches Dokument. Schematisch kann man sich dies folgendermassen vorstellen:

Im obigen Beispiel ist je ein Abschnitt aus den Seiten B und C als Transklusion in die Seite A eingebettet. Wie man sieht, kann eine Seite mehrere Transklusionen enthalten. Umgekehrt könnte derselbe Abschnitt mehrfach in unterschiedliche Seiten eingebettet werden. Auch sonst gibt es keine Beschränkungen: Jede Seite kann beliebig viele Abschnitte als Transklusionen bereitstellen und einbetten.
Dieses Prinzip hat entscheidende Vorteile:
- Im Gegensatz zu einer Kopie ist eine Einbettung dynamisch: Falls also jemand das Original anpasst, aktualisiert sich die Transklusion automatisch. Dadurch sind alle Transklusionen immer auf dem aktuellen Stand, und es können keine unterschiedlichen Versionen entstehen. Zudem ist die Einbettung als solche erkennbar und ihre Herkunft nachvollziehbar.
- Im Gegensatz zu einem Link muss der Leser das Dokument nicht verlassen, um eine referenzierte Stelle in einem anderen Dokument zu konsultieren. Transklusionen erlauben es, in einem Hypertext-System einen linearen Text zu erstellen, der dennoch auf andere Texte Bezug nimmt.
Nun hatte Ted Nelson wohl weniger das persönliche Wissensmanagement als vielmehr das Publizieren in einem globalen Netzwerk vor Augen, wo Textteile von anderen Autoren in eigenen Texten wiederverwendet werden. Aber Transklusionen sind auch in einer persönlichen Wissensbasis von Nutzen. Dank ihnen kann man Informationseinheiten jeglicher Art mehrfach in unterschiedlichen Zusammenhängen verwenden, ohne Kopien erstellen zu müssen. Dadurch bleibt die Wissensbasis redundanz- und widerspruchsfrei – und man weiss jederzeit, woher eine Informationseinheit ursprünglich stammt.
Insbesondere wenn man sich in der Create-Phase des 4C-Modells befindet, sind Transklusionen wertvoll. Erstellt man eine Publikation direkt in seinem Tool for Thought, kann man sein Manuskript sehr einfach mit Elementen aus seinen Notizen ergänzen – sei es nun ein Zitat aus den Literaturnotizen, sei es ein eigener Gedankengang aus den Permanent Notes.
In den Tools for Thought werden Transklusionen üblicherweise als Block Embeds bzw. Block References bezeichnet. Diese können ähnlich wie Links erstellt werden, nur kommt hier statt der doppelten eckigen Klammer die doppelte runde Klammer zum Einsatz. Analog wie beim Setzen von Links öffnet sich nach Eingabe der Klammer eine Liste mit allen Blocks, die nach dem eingetippten Begriff gefiltert wird und so die Auswahl des gewünschten Blocks ermöglicht:

Ist die Transklusion einmal erstellt, so wird sie durch eine spezielle Formatierung als solche kenntlich gemacht. Zudem kann man von der Transklusion zum Ursprungsblock springen. Umgekehrt wird jeder Block, der als Transklusion an anderer Stelle eingebettet wurde, kenntlich gemacht, und man kann sich die Einbettungen direkt anzeigen lassen.
Das folgende Video zeigt, wie Block Embeds und Block References in Logseq funktionieren:
4.3.6 Visualisierung von Graphen
Sowohl Links als auch Transklusionen erzeugen Verbindungen zwischen Seiten bzw. Blocks. Es ist deshalb naheliegend, dass die Tools for Thought die interne Vernetzung einer Wissensbasis auch visuell abbilden, um Zusammenhänge sichtbar zu machen. Dies geschieht in Form eines für Graphen typischen Netzes, bei dem die Seiten als Knoten und die Links als Kanten dargestellt werden. Dabei ist zu unterscheiden zwischen der globalen Graph View und dem seitenspezifischen Page Graph.
Die Graph View zeigt sämtliche vorhandenen Seiten. In unserem Graphen zur Schweizer Demokratie könnte sie beispielsweise so aussehen:

Der Page Graph zeigt dagegen nur diejenigen Seiten, welche mit der aktuellen Seite über einen ausgehenden oder eingehenden Link verbunden sind wie im folgenden Beispiel der Seite «Bundeskanzlei»:

Diese Visualisierung ist auf den ersten Blick sehr attraktiv – in der Praxis hingegen ist sie weit weniger nützlich als man erwarten würde. Insbesondere bei grösseren Graphen bietet die Graph View kaum noch einen Erkenntniswert, wie man am Beispiel meiner persönlichen Wissensbasis in Roam Research sehen kann:

Zwar veranschaulicht diese Visualisierung den Umfang der Wissensbasis, und sie erlaubt es, Seiten mit besonders vielen Links anhand ihrer Grösse zu identifizieren. Damit die Graph View wirklich als Analyseinstrument des eigenen Wissens taugt, bräuchte es allerdings mehr, beispielsweise
- die Möglichkeit, die in der Graph View angezeigten Seiten nach allen denkbaren Kriterien zu filtern
- die Möglichkeit, die Knoten frei zu positionieren und zu kategorisieren (mit Farben, Schlagwörtern etc.)
- die Möglichkeit, nicht nur Links, sondern auch Block Embeds bzw. Block References abzubilden
Am weitesten entwickelt ist die Graph View in Obsidian, sie erfüllt zumindest die beiden ersten Anforderungen recht gut:

Die Graph View hat durchaus Potenzial. In der heutigen Form – und dies gilt insbesondere für Roam Research und Logseq – ist sie allerdings eher eine Spielerei. Aus diesem Grund verzichte ich auf ein Video zu diesem Thema.
4.3.7 Queries
Eine Query ist eine vordefinierte Suchanfrage, die an beliebiger Stelle in eine Seite eingebettet wird. Als Resultat erhält man nicht bloss eine Liste mit den Seiten, welche den Suchkriterien entsprechen, sondern es werden alle passenden Blocks angezeigt.
Die Definition von Queries ist derzeit noch ziemlich technisch: Sie müssen in Code-Form mit einer speziellen Syntax eingegeben werden, die sich zudem von Tool zu Tool unterscheidet. Möchte man beispielsweise alle Blöcke finden, die den Begriff «Bundesrat» enthalten, so würde die Query in Logseq folgendermassen aussehen:
{{query "Bundesrat"}}
Das Resultat wäre in diesem Fall das folgende:

Der Nutzen von Queries liegt darin, dass man wiederholt benötigte Suchvorgänge abspeichern kann, also nicht jedes Mal manuell durchführen muss. Ausserdem erlauben Queries komplexere Suchanfragen als die normale Volltextsuche. So kann man gezielt nach bestimmten Links, Tags oder Properties suchen und dabei auch logische Ausdrücke mit booleschen Operatoren (AND, OR, NOT) verwenden.
Die folgenden Beispiele vermitteln einen Eindruck, wie solche Queries aussehen:
{{query #Bundesrat}}
{{query [[Bundesrat]]}}
|
Findet alle Blöcke, die auf «Bundesrat» verlinken. |
{{query (and "Nationalrat" "Ständerat")}}
|
Findet alle Blöcke, die «Nationalrat» und «Ständerat» enthalten. |
{{query (or "Nationalrat" "Ständerat")}}
|
Findet alle Blöcke, die «Nationalrat» oder «Ständerat» enthalten. |
{{query (property autor "Simonetta Sommaruga")}}
|
Findet alle Blöcke, welche die Eigenschaft «Autor» mit dem Wert «Simonetta Sommaruga» enthalten. |
Insbesondere in Verbindung mit den Properties, die wir im Kapitel «4.3.3 Wiki-Funktionen» behandelt haben, sind die Queries ein interessantes Konzept. Auch wer intensiv mit Hashtags arbeitet, kann sich so Listen generieren lassen mit Blöcken, die bestimmte Hashtag-Kombinationen aufweisen: Der Befehl {{query (and [[CAS-Arbeit]] [[Literatur]] [[Prio 1]])}} etwa liefert jederzeit eine aktuelle Liste der anstehenden Lektüre für eine CAS-Arbeit.
Andererseits sind die Queries nicht sehr benutzerfreundlich: Suchanfragen in Form von Code zu formulieren, dürfte vielen Wissensarbeitern zu umständlich sein – zumal man nicht einmal die etablierte Datenbank-Abfragesprache SQL nutzen kann. Und gerade im Vergleich mit letzterer sind die Möglichkeiten von Queries im Moment noch sehr limitiert (ausser man nutzt die sogenannten Advanced Queries, die in Datalog programmiert werden müssen, was dann nochmals deutlich komplizierter ist als die hier gezeigten Simple Queries). [36]
Das folgende Video zeigt, wie Queries in Logseq funktionieren:
4.3.8 Journal
Typisch für die Tools for Thought ist auch das Journal, das standardmässig angezeigt wird, wenn man das Programm startet. Rein technisch betrachtet besteht das Journal aus normalen Seiten mit einem Datum im Titel. Die einzige Besonderheit besteht darin, dass die Journalseite des aktuellen Tages automatisch angelegt wird und dass man über einen Kalender zu einer beliebigen Journalseite navigieren kann.
Das Journal eignet sich insbesondere für datumsbezogene Notizen – seien es zu erledigende Aufgaben, seien es Besprechungsprotokolle, seien es Einträge mit Tagebuchcharakter. Hier kann man seine Wissensarbeit planen und dokumentieren.

Viele Nutzer der Tools for Thought gehen noch einen Schritt weiter: Sie verfassen praktisch ihre gesamten Notizen im Journal. Dies steht auf den ersten Blick im Widerspruch zu den Prinzipien der Zettelkasten-Methode, bei der es ja genau darum geht, Notizen nicht einfach chronologisch abzulegen, sondern in eine Wissensbasis einzuarbeiten.
Hier kommen allerdings die bidirektionalen Links ins Spiel: Sofern man die Notizen, die man im Journal macht, mit geeigneten Links bzw. Hashtags versieht, erscheinen sie bei den entsprechenden Begriffen unter den Linked References und sind damit in die Wissensbasis integriert. Hier zeigt sich einmal mehr, dass man sich dank der bidirektionalen Links keine Gedanken darüber zu machen braucht, wo eine Notiz platziert werden soll: Solange die Notiz sinnvoll verlinkt ist, ist jeder Ort der richtige.
[29] Burckhardt 2021.
[30] Oudt 2022.
[31] Zu präzisieren wäre an dieser Stelle, dass die Tools for Thought Notizen auch als einzelne Textdatei im Markup-Format ablegen können. Logseq macht dies standardmässig im Hintergrund, bei Roam muss man es über die Exportfunktion explizit veranlassen. Entscheidend ist aber, dass man als Benutzer nicht mit einzelnen Dateien interagiert, sondern nur mit der Datenbank.
[32] Rink 2022a.
[33] Bush 1945.
[34] Nelson kritisiert bis heute, dass das von Tim Berners-Lee entwickelte Word Wide Web keine bidirektionalen Links kennt (z.B. in Nelson 2017). Stefan Münz hingegen hat überzeugend dargelegt, warum bidirektionale Links in einem offenen Hypertextsystem problematisch wären (Münz 2009).
[35] Matuschak o.J., https://notes.andymatuschak.org/Contextual_backlinks